Prepararsi al data lake per la scalabilità del sistema ENPAS
Il presente articolo riporta la differenza sostanziale tra il Data Warehouse e i Data Lakes e come quest’ultimi possano creare un valore aggiunto in un futuro sviluppo del sistema Enpas.
Il sistema EnPAS (plug and play Energy and Production Assessment System), consiste in un sistema integrato e adattivo di misurazione exergetica dei processi produttivi di tipo Plug&Play. Il progetto di ricerca è stato focalizzato nello sviluppo di un sistema hardware che permetterà di acquisire mediante diversi protocolli i dati a livello di campo (ad es. dai sensori installati sulle singole macchine o su una intera linea produttiva di un processo manifatturiero) e di inviarli alla piattaforma software che fungerà da “cervello” dell’intero sistema. La piattaforma di controllo e gestione, quindi, recepisce i dati aggregati dalle fonti informative generate dai differenti oggetti e, sulla base del sistema di indicatori e degli algoritmi decisionali sviluppati, effettua il supporto alle decisioni.
L’architettura EnPAS proposta è stata strutturata, così come mostrato in figura seguente, secondo due macro-layers:
o Application Layer;
o Field Layer.
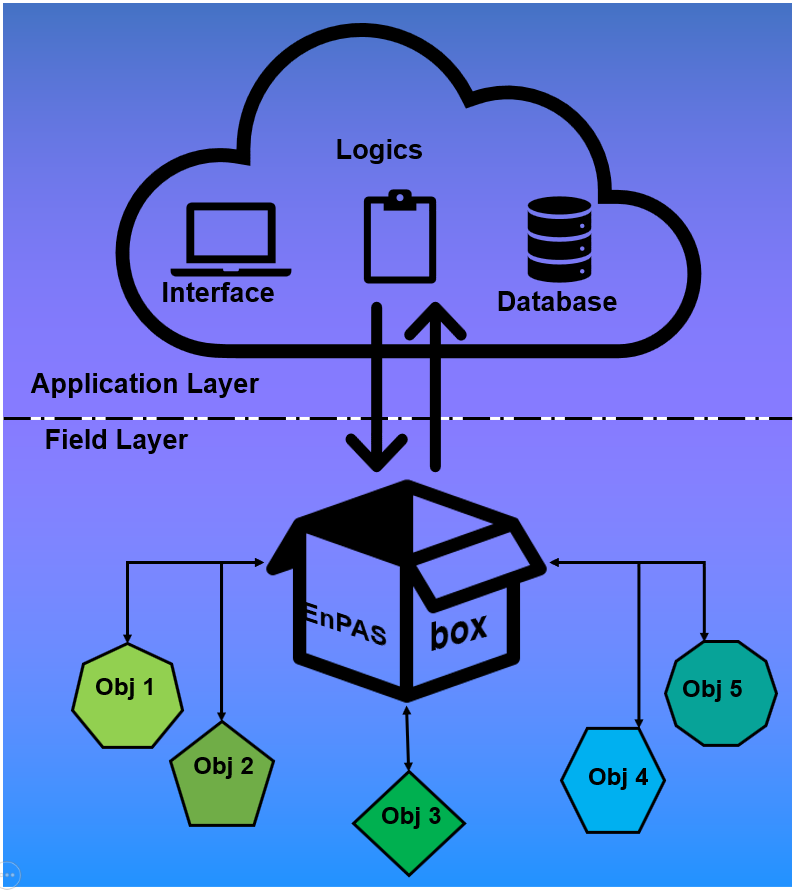
L’architettura prevista nel progetto ha previsto inizialmente l’utilizzo di un Data Warehouse. Al fine di scalare il sistema verso l’utilizzo estensivo dei dati e la loro analisi approfondita è stata studiata anche l’opportunità dell’utilizzo di un Data Lake. Ma quale può essere il vantaggio di una tale architettura? La risposta la si può trovare analizzando la differenza tra i Data Warehouse e i Data Lakes.
Data Warehouse vs. Data Lakes
Esistono diverse modalità per conservare big data, ma la selezione di Data Warehouse e Data Lake dipende da chi utilizza i dati e come.
I Data Lake
- Salva i dati grezzi e può manipolare senza considerare la struttura e il formato dei dati in precedenza. Le informazioni sono strutturate solo quando i dati devono essere estratti e valutati nei data lake.
- Contemporaneamente, il processo di analisi non altera i dati disponibili nel lago, ovvero i dati rimangono non strutturati in modo da poter essere depositati e utilizzati anche per altri scopi.
- Inoltre, i dati possono essere archiviati così come sono indipendentemente dalla prima conversione della struttura dei dati e condurre analisi diverse, da dashboard e visualizzazioni a trasformazioni di big data , analisi in tempo reale e apprendimento automatico per prendere le decisioni aziendali più adeguate.
I Data Warehouse
Il Data Warehouse aiuta il flusso di dati dai sistemi operativi non convenzionali ai sistemi di interpretazione o soluzione creando un unico sistema di repository di dati provenienti da varie fonti mediante massicci processi ETL (è un’espressione in lingua inglese che si riferisce al processo di estrazione, trasformazione e caricamento dei dati in un sistema di sintesi: Extract, Transform, Load).
Le origini dei dati possono essere diverse e mostrare rappresentazioni dei dati separate che producono informazioni divergenti come contabilità, informatica, fatturazione, ecc. Inoltre, numerosi modelli di dati lo rendono complicato per ottenere opinioni consolidate quando da tutti i sistemi applicativi è necessaria un’interpretazione completa , per questo motivo sono entrate in gioco le soluzioni di Data Warehouse.
Con l’aiuto del database relazionale è possibile progettare un Data Warehouse. Ha un’architettura multistrato compatta, nota come Layered Scalable Architecture (LSA) in cui LSA utilizza una distribuzione logica della struttura insieme ai dati in vari livelli funzionali. I dati vengono quindi estratti da uno strato all’altro e convertiti in informazioni stabili, appropriate per l’analisi.
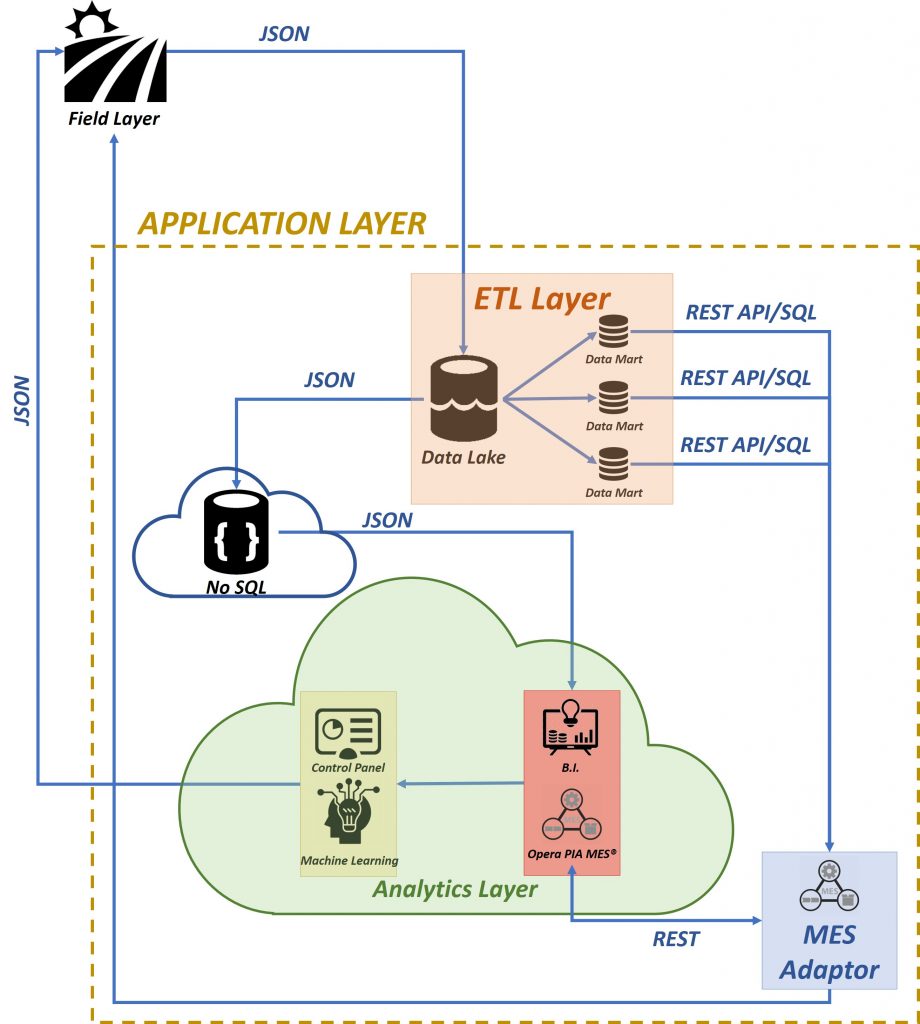
Con l’aumento del valore e della qualità dei dati non strutturati, anche la popolarità del data lake aumenterà contemporaneamente, ma ci sarà invariabilmente un punto imperativo per data warehouse e database. Probabilmente, continuare ad archiviare dati strutturati nei data warehouse è una buona opzione, ma poiché diverse organizzazioni stanno adottando di spostare i propri dati non strutturati in data lake sul cloud dove è più utile immagazzinarli e spostarli agevolmente quando necessario. Il carico di lavoro che incorpora i data lake, il data warehouse o persino il database in diversi modi è utile.
